前几天写的关于"大数据"的文章,收到了很多小伙伴们的认可,"大数据"这几年确实很火,那么小伙伴们知道"大数据"里的"数据"是从怎么来的吗?
我们可以简单来列举一下:
1.企业生产的用户数据
比如像BAT等公司,拥有庞大的用户群体,用户的任何行为都会成为他们数据源的一部分
2.数据平台购买数据
比如从国家数据中心 数据市场等购买。
3. 政府 机构公开数据
比如统计局 银行公开数据等。
4. 数据管理公司
比如艾瑞咨询等。
5.爬虫获取网络数据
通过网络爬虫技术,爬去网络数据,以供使用。
那么其实对于中小企业或者个人想获取"大数据或者海量数据",性价比最高的方法就是利用"网络爬虫技术"来获取有效数据,所以近些年"网络爬虫技术"也非常的火爆!
今天我就给大家阐述一下"网络爬虫技术原理与实现"!
一、什么是网络爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。简单点说就是一段自动化执行的程序,它会请求网站并提取数据。
最出名的网络爬虫应用算是Google和百度的网络爬虫。
这两大搜索引擎每天都要爬取网络上海量的数据,然后再做数据分析处理,最后通过搜索展示给我们,可以说网络爬虫是搜索引擎的根基!
二、网络爬虫的工作流程和原理网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。
(一)、网络爬虫的基本结构及工作流程
一个通用的网络爬虫的框架如图所示:
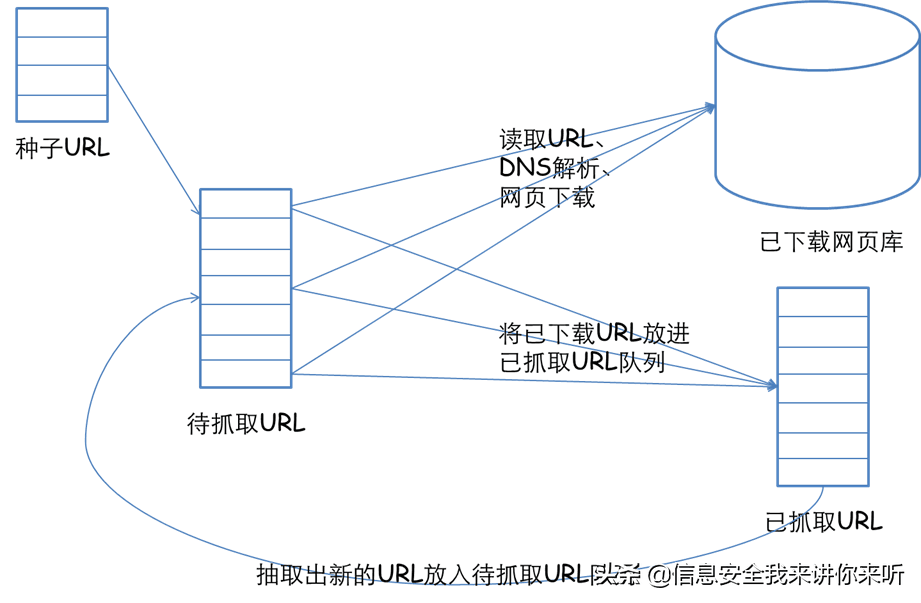
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
(二)、从爬虫的角度对互联网进行划分
对应的,可以将互联网的所有页面分为五个部分:
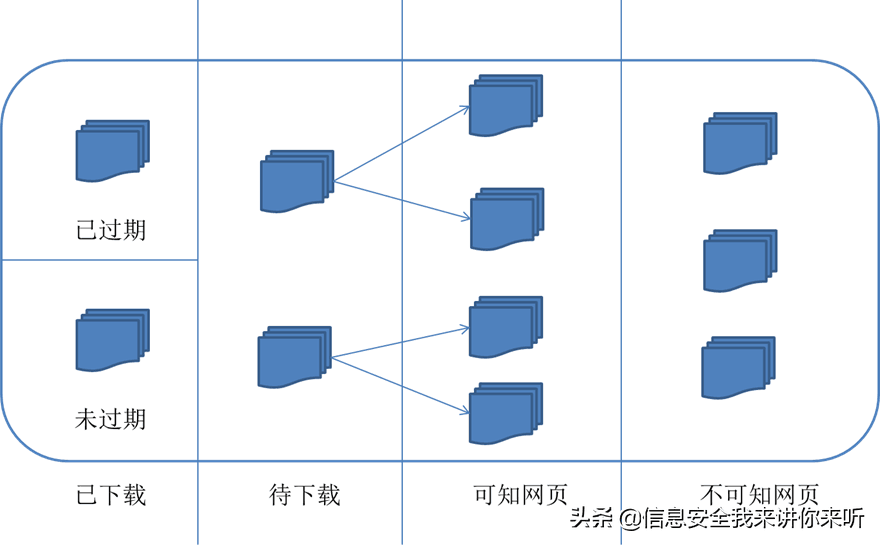
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容已经发生了变化,这时,这部分抓取到的网页就已经过期了。
3.待下载网页:也就是待抓取URL队列中的那些页面
4.可知网页:还没有抓取下来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或者待抓取URL对应页面进行分析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是无法直接抓取下载的。称为不可知网页。
(三)、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
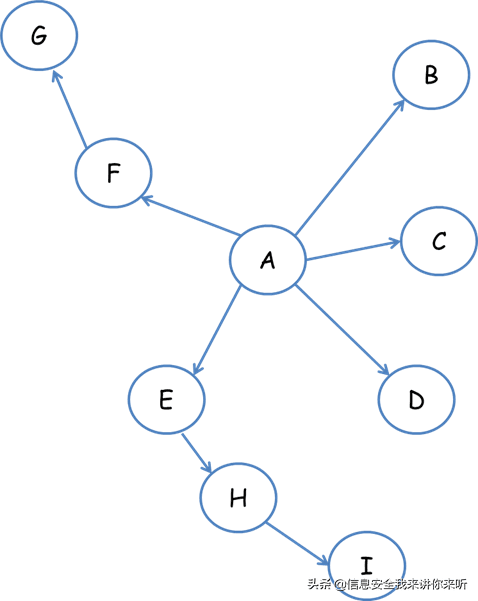
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
(四)、更新策略
互联网是实时变化的,具有很强的动态性。网页更新策略主要是决定何时更新之前已经下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面以往的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略 尽管搜索引擎针对于某个查询条件能够返回数量巨大的结果,但是用户往往只关注前几页结果。因此,抓取系统可以优先更新那些现实在查询结果前几页中的网页,而后再更新那些后面的网页。这种更新策略也是需要用到历史信息的。用户体验策略保留网页的多个历史版本,并且根据过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的依据。 3.聚类抽样策略
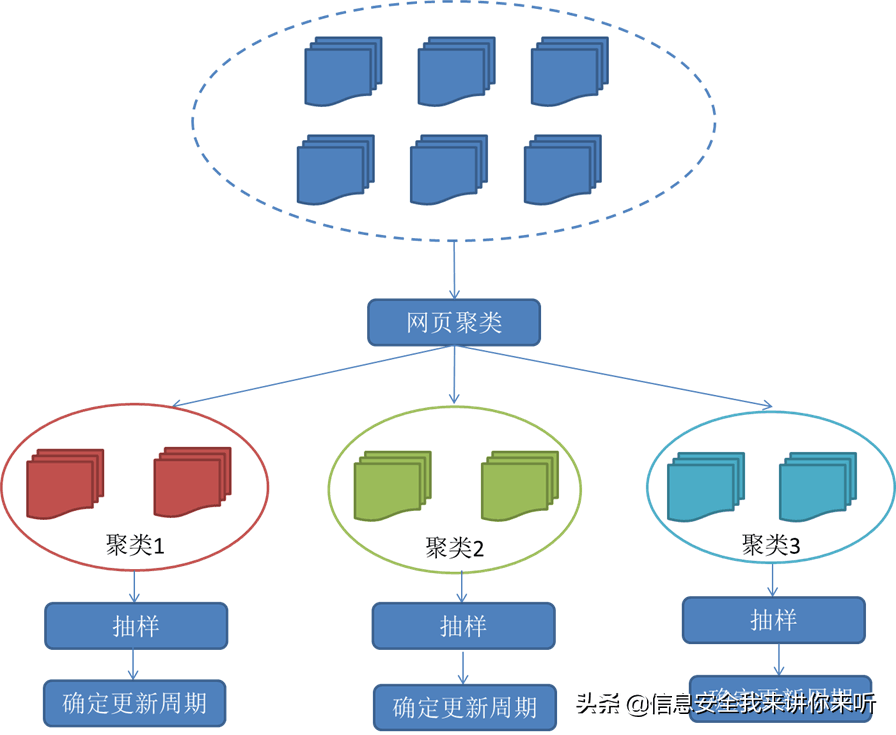
前面提到的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一,系统要是为每个系统保存多个版本的历史信息,无疑增加了很多的系统负担;第二,要是新的网页完全没有历史信息,就无法确定更新策略。
这种策略认为,网页具有很多属性,类似属性的网页,可以认为其更新频率也是类似的。要计算某一个类别网页的更新频率,只需要对这一类网页抽样,以他们的更新周期作为整个类别的更新周期。基本思路如图:
(五)、分布式抓取系统结构 一般来说,抓取系统需要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往需要多个抓取程序一起来处理。一般来说抓取系统往往是一个分布式的三层结构。如图所示:
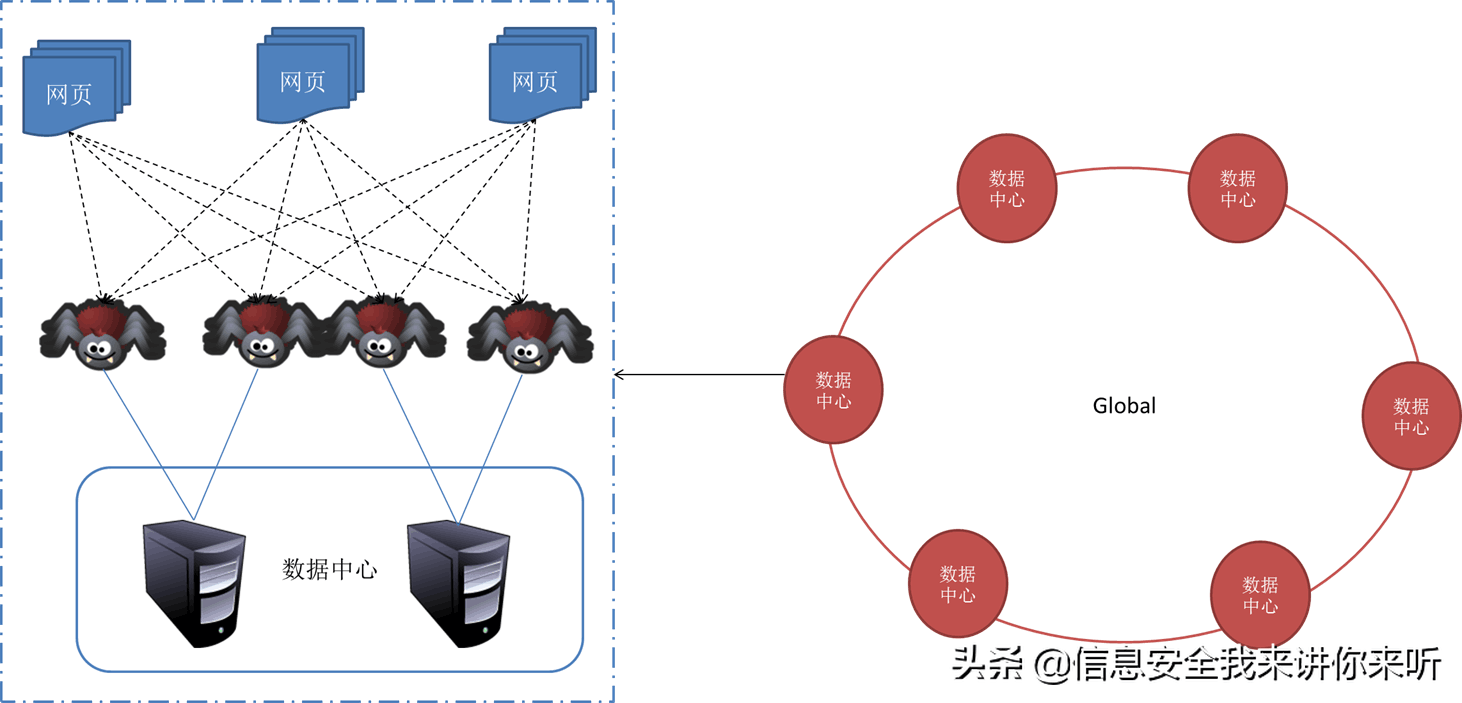
最下一层是分布在不同地理位置的数据中心,在每个数据中心里有若干台抓取服务器,而每台抓取服务器上可能部署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方式有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
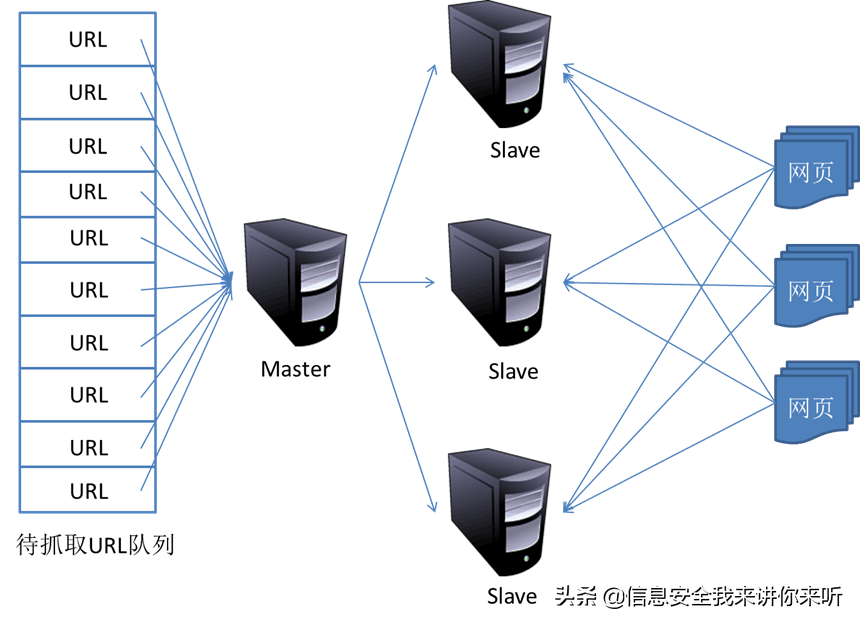
对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器除了维护待抓取URL队列以及分发URL之外,还要负责调解各个Slave服务器的负载情况。以免某些Slave服务器过于清闲或者劳累。
这种模式下,Master往往容易成为系统瓶颈。
2.对等式(Peer to Peer)
对等式的基本结构如图所示:
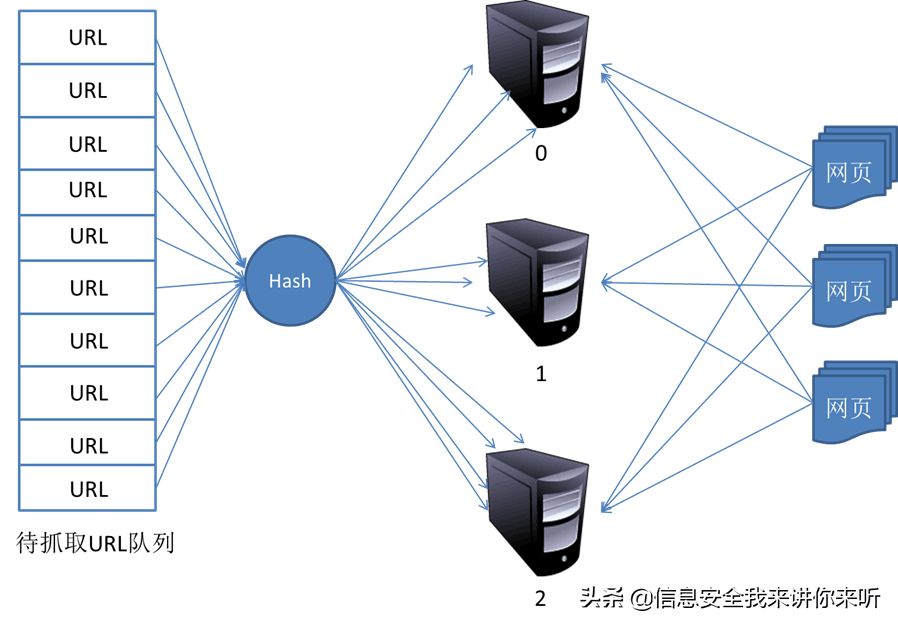
在这种模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后计算H mod m(其中m是服务器的数量,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL www.baidu.com,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器拿到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器死机或者添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方式的扩展性不佳。针对这种情况,又有一种改进方案被提出来。这种改进的方案是一致性哈希法来确定服务器分工。
其基本结构如图所示:
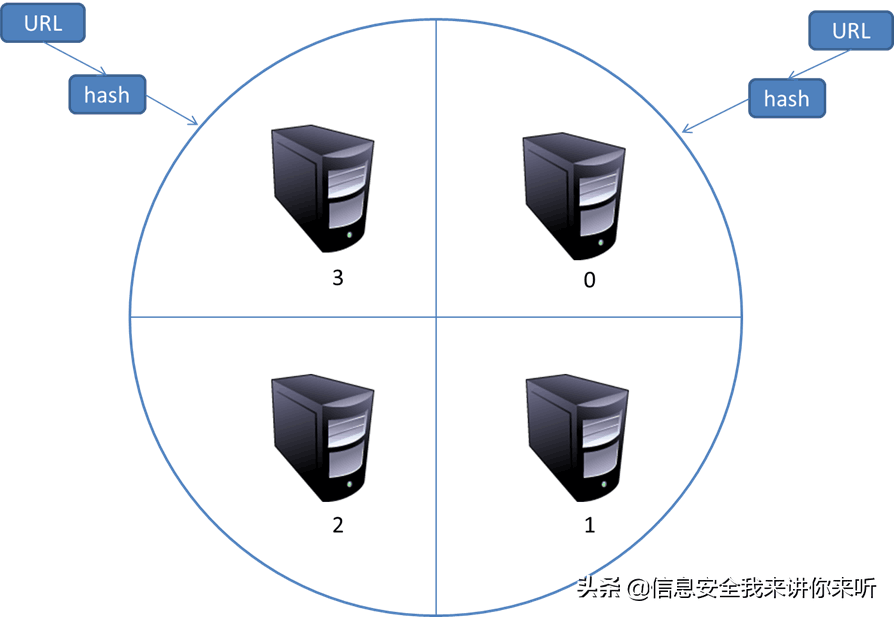
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-232之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判断是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则按照顺时针顺延,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。
三、常见网络爬虫的类型1.通用网络爬虫(General Purpose Web Crawler)
爬取目标资源在全互联网中,爬取目标数据巨大。对爬取性能要求非常高。应用于大型搜索引擎中,有非常高的应用价值。
通用网络爬虫的基本构成:初始URL集合,URL队列,页面爬行模块,页面分析模块,页面数据库,链接过滤模块等构成。
通用网络爬虫的爬行策略:主要有深度优先爬行策略和广度优先爬行策略。
2.聚焦网络爬虫(Focused Crawler)
将爬取目标定位在与主题相关的页面中
主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务
聚焦网络爬虫的基本构成:初始URL,URL队列,页面爬行模块,页面分析模块,页面数据库,连接过滤模块,内容评价模块,链接评价模块等构成
聚焦网络爬虫的爬行策略:
1) 基于内容评价的爬行策略
2) 基于链接评价的爬行策略
3) 基于增强学习的爬行策略
4) 基于语境图的爬行策略
3.增量式网络爬虫(Incremental Web Crawler)
增量式更新指的是在更新的时候只更新改变的地方,而未改变的地方则不更新,只爬取内容发生变化的网页或者新产生的网页,一定程度上能保证所爬取的网页,尽可能是新网页
4.深层网络爬虫(Deep Web Crawler)
表层网页:不需要提交表单,使用静态的链接就能够到达的静态网页
深层网页:隐藏在表单后面,不能通过静态链接直接获得,是需要提交一定的关键词之后才能够获取得到的网页。
深层网络爬虫最重要的部分即为表单填写部分
深层网络爬虫的基本构成:URL列表,LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)爬行控制器,解析器,LVS控制器,表单分析器,表单处理器,响应分析器等
深层网络爬虫表单填写有两种类型:
基于领域知识的表单填写(建立一个填写表单的关键词库,在需要的时候,根据语义分析选择对应的关键词进行填写)
基于网页结构分析的表单填写(一般是领域只是有限的情况下使用,这种方式会根据网页结构进行分析,并自动的进行表单填写)
四、教你如何实现一个简单的网络爬虫(一)、爬虫流程
构建程序前,我们首先需要了解爬虫的具体流程。
一个简易的爬虫程序,具备以下流程:
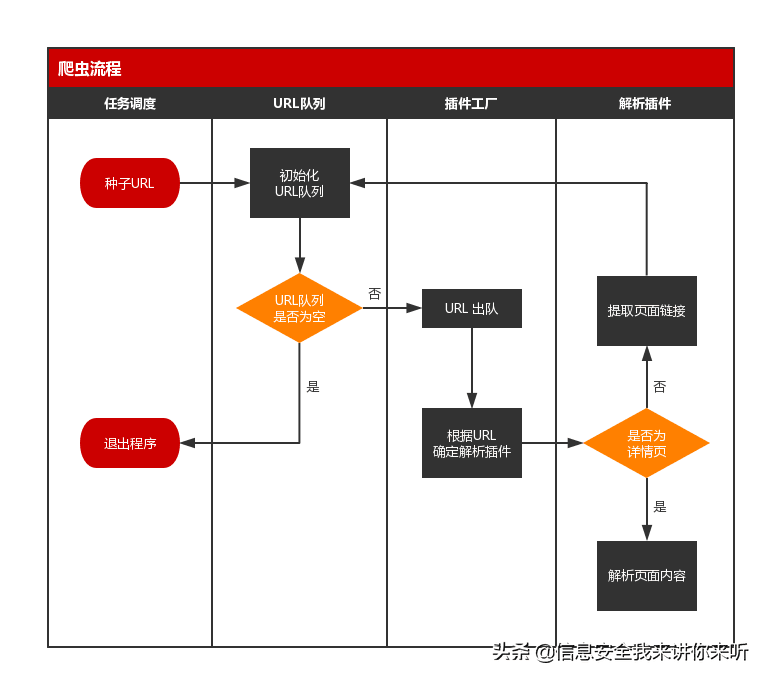
若以文字表述,就是:
1、从任务库(可以是 MySQL 等关系型数据库)选取种子 URL;
2、在程序中初始化一个 URL 队列,将种子 URL 加入到队列中;
3、若 URL 队列不为空,则位于队头的 URL 出队;若 URL 队列为空,则退出程序;
4、程序根据出列的 URL,反射出对应的解析类,同时新建线程,开始解析任务;
5、程序将下载 URL 指向的网页,并判断该页面是详情页还是列表页(如博客中的博客详情与博文列表),若为详情页,则解析出页面内容并入库,若为列表页,则提取出页面链接,加入到 URL 队列中;
6、解析任务完成后,重复第 3 步。
(二)、程序结构
我们已经清楚爬虫的具体流程,现在,我们需要一个合理的程序结构来实现它。
首先,介绍一下该简易爬虫程序的主要结构组成:
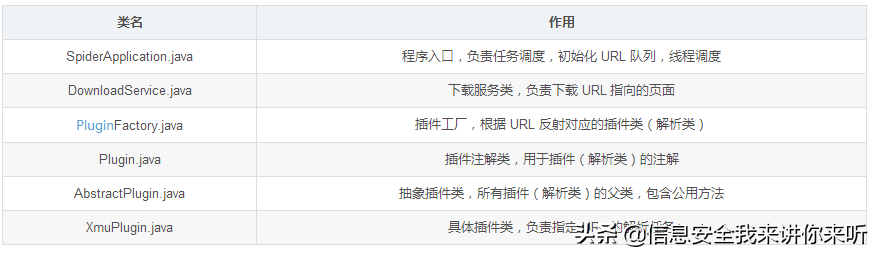
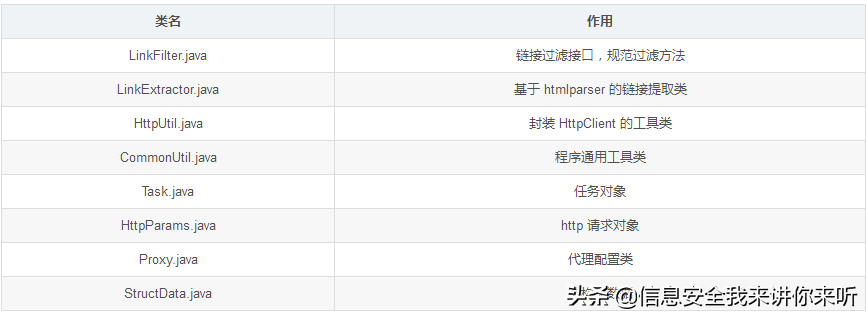
然后,再了解一下程序中的工具类与实体类。
最后,我们根据类的作用,将其放置到上述流程图中对应的位置中。具体的示意图如下所示:
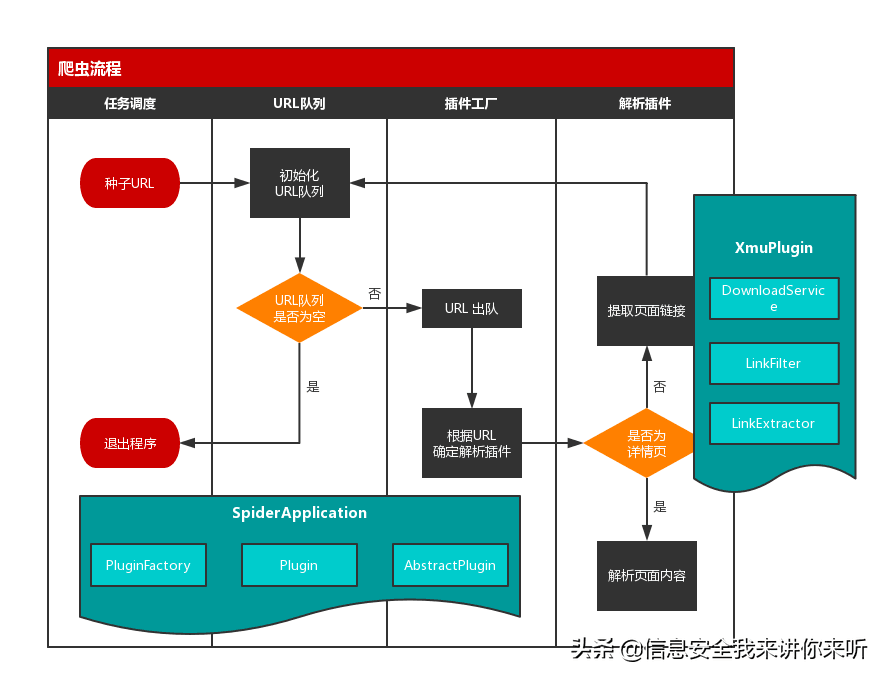
现在,我们已经完成了实际流程到程序逻辑的转换。接下来,我们将通过源码的介绍,深入到程序中的各个细节。
(三)、任务调度、初始化队列
在简易爬虫程序中,任务调度、初始化队列都在 SpiderApplication 类中完成。
(四)、插件工厂
在 URL 循环调度中,有个语句需要我们注意:
AbstractPlugin plugin = PluginFactory.getInstance().getPlugin(task);
其中,AbstractPlugin 是一个继承 Thread 的抽象插件类。
该语句的意思是,由插件工厂,根据 url,反射实例化继承了 AbstractPlugin 的指定插件。
插件工厂,也可以理解为解析类工厂。
在本程序中,插件工厂的实现主要依靠三方面:
1. Plugin
package plugins;
import java.lang.annotation.*;
/**
* 插件注解
*
* @author panda
* @date 2017/12/01
*/
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Plugin {
String value() default "";
}
Plugin 实际上是一个注解接口,有 Plugin 的支持,我们可以实现让程序通过注解 @Plugin 来识别插件类。这就像 SpringMVC 中,我们通过 @Controller、@Service 等识别一个个 Bean。
2.XmuPlugin
@Plugin(value = "sm.xmu.edu.cn")
public class XmuPlugin extends AbstractPlugin {
}
XmuPlugin 是众多插件(解析类)之一,由注解 @Plugin 标志角色,由注解中的 value 标志其具体身份(即对应哪个 url)。
3.PluginFactory
package factory;
import entity.Task;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import plugins.AbstractPlugin;
import plugins.Plugin;
import util.CommonUtil;
import java.io.File;
import java.lang.annotation.Annotation;
import java.lang.reflect.Constructor;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 插件工厂
*
* @author panda
* @date 2017/12/01
*/
public class PluginFactory {
private static final Logger logger = LoggerFactory.getLogger(PluginFactory.class);
private static final PluginFactory factory = new PluginFactory();
private List<Class<?>> classList = new ArrayList<Class<?>>();
private Map<String, String> pluginMapping = new HashMap<String, String>();
private PluginFactory() {
scanPackage("plugins");
if (classList.size() > 0) {
initPluginMapping();
}
}
public static PluginFactory getInstance() {
return factory;
}
/**
* 扫描包、子包
*
* @param packageName
*/
private void scanPackage(String packageName) {
try {
String path = getSrcPath() + File.separator + changePackageNameToPath(packageName);
File dir = new File(path);
File[] files = dir.listFiles();
if (files == null) {
logger.warn("包名不存在!");
return;
}
for (File file : files) {
if (file.isDirectory()) {
scanPackage(packageName + "." + file.getName());
} else {
Class clazz = Class.forName(packageName + "." + file.getName().split("\.")[0]);
classList.add(clazz);
}
}
} catch (Exception e) {
logger.error("扫描包出现异常:", e);
}
}
/**
* 获取根路径
*
* @return
*/
private String getSrcPath() {
return System.getProperty("user.dir") +
File.separator + "src" +
File.separator + "main" +
File.separator + "java";
}
/**
* 将包名转换为路径格式
*
* @param packageName
* @return
*/
private String changePackageNameToPath(String packageName) {
return packageName.replaceAll("\.", File.separator);
}
/**
* 初始化插件容器
*/
private void initPluginMapping() {
for (Class<?> clazz : classList) {
Annotation annotation = clazz.getAnnotation(Plugin.class);
if (annotation != null) {
pluginMapping.put(((Plugin) annotation).value(), clazz.getName());
}
}
}
/**
* 通过反射实例化插件对象
* @param task
* @return
*/
public AbstractPlugin getPlugin(Task task) {
if (task == null || task.getUrl() == null) {
logger.warn("非法的任务!");
return null;
}
if (pluginMapping.size() == 0) {
logger.warn("当前包中不存在插件!");
return null;
}
Object object = null;
String pluginName = CommonUtil.getHost(task.getUrl());
String pluginClass = pluginMapping.get(pluginName);
if (pluginClass == null) {
logger.warn("不存在名为 " + pluginName + " 的插件");
return null;
}
try {
logger.info("找到解析插件:" + pluginClass);
Class clazz = Class.forName(pluginClass);
Constructor constructor = clazz.getConstructor(Task.class);
object = constructor.newInstance(task);
} catch (Exception e) {
logger.error("反射异常:", e);
}
return (AbstractPlugin) object;
}
}
PluginFactory 的作用主要是两个:
扫描插件包下有 @Plugin 注解的插件类;
根据 url 反射指定插件类。
(五)、解析插件
我们上面说到,解析插件实际上就是对应一个个网站的解析类。
由于实际爬虫的解析中,总有许多解析工作是相似甚至相同的,例如链接提取,因此,在解析插件中,我们首先要实现一个父接口,来提供这些公用方法。
本程序中,插件父接口即上面提到的 AbstractPlugin 类:
package plugins;
import entity.Task;
import filter.AndFilter;
import filter.FileExtensionFilter;
import filter.LinkExtractor;
import filter.LinkFilter;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import service.DownloadService;
import util.CommonUtil;
import java.util.ArrayList;
import java.util.List;
/**
* 插件抽象类
*
* @author panda
* @date 2017/12/01
*/
public abstract class AbstractPlugin extends Thread {
private static final Logger logger = LoggerFactory.getLogger(AbstractPlugin.class);
protected Task task;
protected DownloadService downloadService = new DownloadService();
private List<String> urlList = new ArrayList<String>();
public AbstractPlugin(Task task) {
this.task = task;
}
@Override
public void run() {
logger.info("{} 开始运行...", task.getUrl());
String body = downloadService.getResponseBody(task);
if (StringUtils.isNotEmpty(body)) {
if (isDetailPage(task.getUrl())) {
logger.info("开始解析详情页...");
parseContent(body);
} else {
logger.info("开始解析列表页...");
extractPageLinks(body);
}
}
}
public void extractPageLinks(String body) {
LinkFilter hostFilter = new LinkFilter() {
String urlHost = CommonUtil.getUrlPrefix(task.getUrl());
public boolean accept(String link) {
return link.contains(urlHost);
}
};
String[] fileExtensions = (".xls,.xml,.txt,.pdf,.jpg,.mp3,.mp4,.doc,.mpg,.mpeg,.jpeg,.gif,.png,.js,.zip," +
".rar,.exe,.swf,.rm,.ra,.asf,.css,.bmp,.pdf,.z,.gz,.tar,.cpio,.class").split(",");
LinkFilter fileExtensionFilter = new FileExtensionFilter(fileExtensions);
AndFilter filter = new AndFilter(new LinkFilter[]{hostFilter, fileExtensionFilter});
urlList = LinkExtractor.extractLinks(task.getUrl(), body, filter);
}
public List<String> getUrlList() {
return urlList;
}
public abstract void parseContent(String body);
public abstract boolean isDetailPage(String url);
}
父接口定义了两个规则:
解析规则,即什么时候解析正文,什么时候提取列表链接;
提取链接规则,即过滤掉哪些不需要的链接。
但是我们注意到,父接口中用来解析网站正文内容的 parseContent(String body) 是抽象方法。而这,正是实际的插件类应该完成的事情。这里,我们以 XmuPlugin 为例:
package plugins;
import entity.Task;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import util.CommonUtil;
import util.FileUtils;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* xmu 插件
*
* @author panda
* @date 2017/12/01
*/
@Plugin(value = "sm.xmu.edu.cn")
public class XmuPlugin extends AbstractPlugin {
private static final Logger logger = LoggerFactory.getLogger(XmuPlugin.class);
public XmuPlugin(Task task) {
super(task);
}
@Override
public void parseContent(String body) {
Document doc = CommonUtil.getDocument(body);
try {
String title = doc.select("p.h1").first().text();
String publishTimeStr = doc.select("div.right-content").first().text();
publishTimeStr = CommonUtil.match(publishTimeStr, "(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})")[1];
Date publishTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(publishTimeStr);
String content = "";
Elements elements = doc.select("p.MsoNormal");
for (Element element : elements) {
content += "n" + element.text();
}
logger.info("title: " + title);
logger.info("publishTime: " + publishTime);
logger.info("content: " + content);
FileUtils.writeFile(title + ".txt", content);
} catch (Exception e) {
logger.error(" 解析内容异常:" + task.getUrl(), e);
}
}
@Override
public boolean isDetailPage(String url) {
return CommonUtil.isMatch(url, "&a=show&catid=\d+&id=\d+");
}
}
在 XmuPlugin 中,我们做了两件事:
定义详文页的具体规则;
解析出具体的正文内容。
(六)、采集示例
至此,我们成功地完成了 Java 简易爬虫程序,下面,让我们看下实际的采集情况。
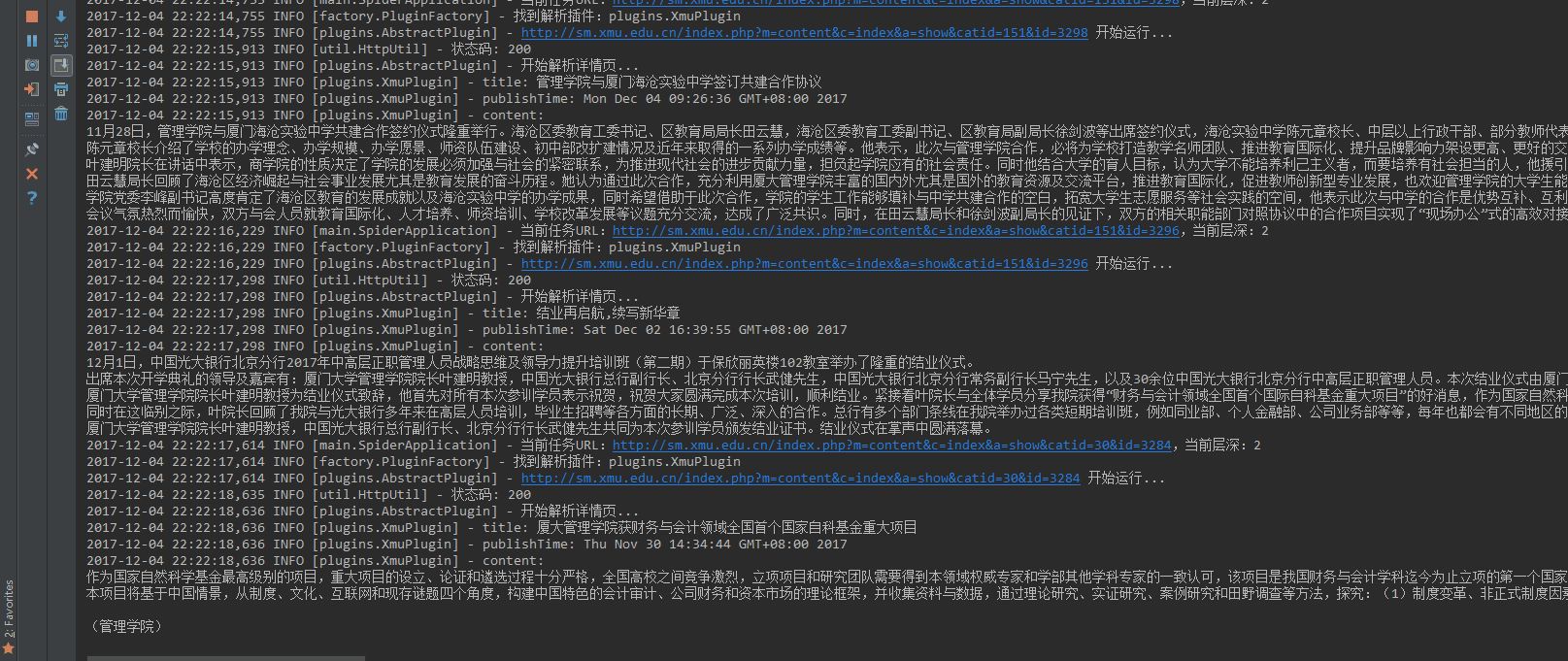 五、分享几款好用的网络爬虫工具和使用教程
五、分享几款好用的网络爬虫工具和使用教程
很多人看了文章会说写的文章太深奥了还要用到编程才能实现数据爬取,有没有简单的方法或者工具可以实现呢? 解下来就给大家分享几款好用的网络爬虫工具,使用起来很简单并且也可以达到对应效果。
1、 神箭手云爬虫
官网:https://www.shenjian.io/
简介:神箭手云是一个大数据应用开发平台,为开发者提供成套的数据采集、数据分析和机器学习开发工具,为企业提供专业化的数据抓取、数据实时监控和数据分析服务。
优点:功能强大,涉及云爬虫、API、机器学习、数据清洗、数据出售、数据订制和私有化部署等;
纯云端运行,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础使用者可直接调用开发好的爬虫,开发者基于官方的云端开发环境开发并上传出售自己的爬虫程序;
领先的反爬技术,例如直接接入代理IP和自动登录验证码识别等,全程自动化无需人工参与;
丰富的发布接口,采集结果以丰富表格化形式展现;
缺点:它的优点同时也在一定程度上成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来非常的偏技术非常专业,尽管官方也提供了云爬虫市场这样的现成爬虫产品,并且开放给广大爬虫开发者,从而让爬虫市场的内容更加丰富,但是对于零技术基础的用户而言并不是那么容易理解,所以有一定的使用门槛。
是否免费:免费用户无采集功能和导出限制,无需积分。
具备开发能力的用户可以自行开发爬虫,达到免费效果,没有开发能力的用户需要从爬虫市场寻找是否有免费的爬虫。
2、 八爪鱼采集器
官网:http://www.bazhuayu.com/
简介:八爪鱼采集器是一款可视化采集器,内置采集模板,支持各种网页数据采集。
优点:支持自定义模式,可视化采集操作,容易上手;
支持简易采集模式,提供官方采集模板,支持云采集操作;
支持防屏蔽措施,例如代理IP切换和验证码服务;
支持多种数据格式导出。
缺点:功能使用门槛较高,本地采集时很多功能受限,而云采集收费较高;
采集速度较慢,很多操作都要卡一下,云端采集说10倍提速但是并不明显;
只支持Windows版本,不支持其他操作系统。
是否免费:号称免费,但是实际上导出数据需要积分,可以做任务攒积分,但是正常情况下基本都需要购买积分。
3、 后羿采集器
官网
:
http://www.houyicaiji.com/简介:后羿采集器是由前谷歌搜索技术团队基于人工智能技术研发的新一代网页采集软件,该软件功能强大,操作极其简单。
优点:支持智能采集模式,输入网址就能智能识别采集对象,无需配置采集规则,操作非常简单;
支持流程图模式,可视化操作流程,能够通过简单的操作生成各种复杂的采集规则;
支持防屏蔽措施,例如代理IP切换等;
支持多种数据格式导出;
支持定时采集和自动化发布,发布接口丰富;
支持Windows、Mac和Linux版本。
缺点:软件推出时间不长,部分功能还在继续完善,暂不支持云采集功能
是否免费:完全免费,采集数据和手动导出采集结果都没有任何限制,不需要积分
4、 利用“八爪鱼采集器”爬数据实例
使用八爪鱼采集瀑布流网站图片(以百度图片采集
为例)的方法。
采集网站:http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1511164186444_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&hs=2&word=%E5%A4%8F%E7%9B%AE%E5%8F%8B%E4%BA%BA%E5%B8%90
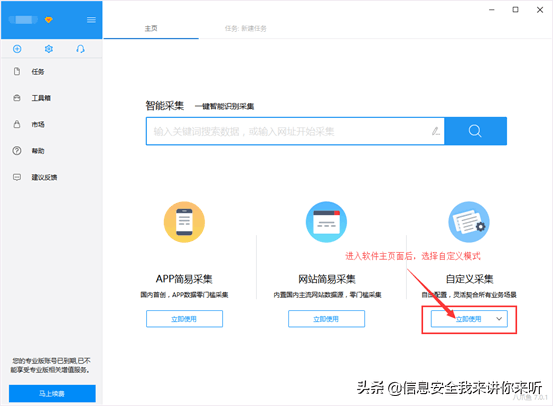
步骤1:创建采集任务1)进入主界面,选择自定义模式
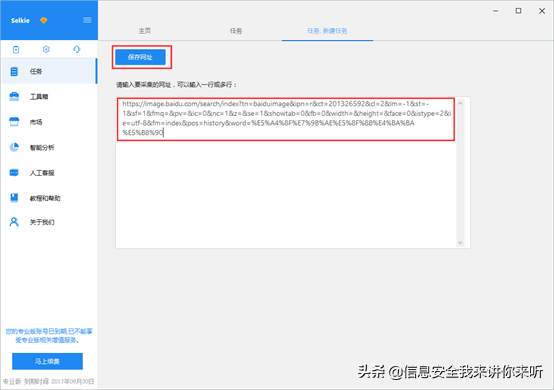
2)将上面网址的网址复制粘贴到网站输入框中,点击"保存网址"
3)系统自动打开网页。我们发现,百度图片网是瀑布流的网页,经过每一次下拉加载,都会出现新的数据。当图片足够多的时候,可无数次下拉加载。因而,此网页涉及AJAX技术,需要设置 AJAX 超时,以便确保数据采集的时候不会遗漏。
选中"打开网页"步骤,打开"高级选项",勾选"页面加载完成向下滚动",设置滚动次数为"5次"(根据自身需求进行设置),时间为"2秒",滚动方式为"向下滚动一屏";最后点击"确定"

注意:示例网站,没有翻页按钮,滚动次数、滚动方式会影响数据采集数量,可按需设置
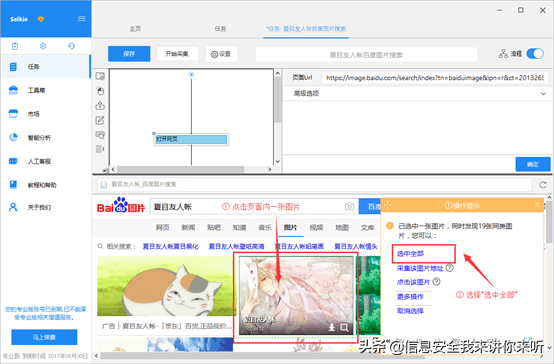
步骤2:采集图片URL1)选中页面内第一个图片,系统会自动识别同类图片。在操作提示框中,选择"选中全部"
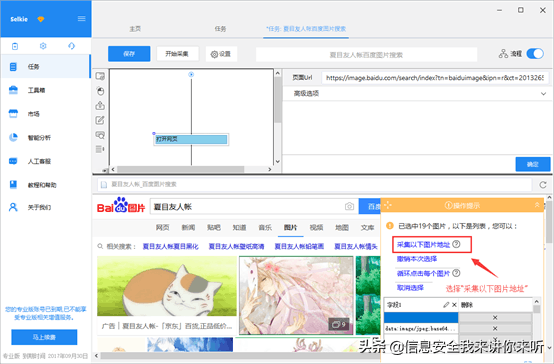
2)选择"采集以下图片地址"
 步骤3:修改Xpath
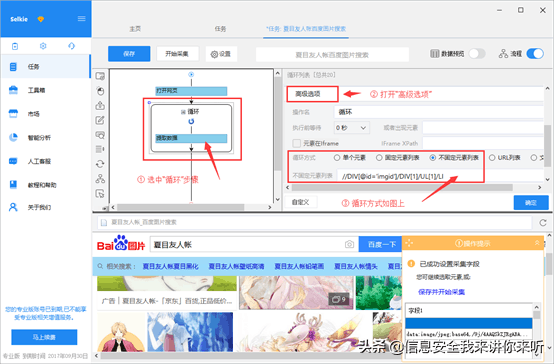
步骤3:修改Xpath1)选中"循环"步骤,打开"高级选项"。可以看到八爪鱼系统自动采用的是"不固定元素列表"循环,Xpath为://DIV[@id=imgid]/DIV[1]/UL[1]/LI
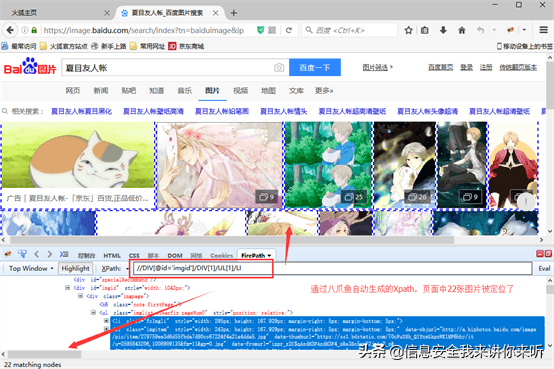
2)将此条Xpath://DIV[@id=imgid]/DIV[1]/UL[1]/LI,复制到火狐浏览器中进行观察——仅可定位到网页中22张图片
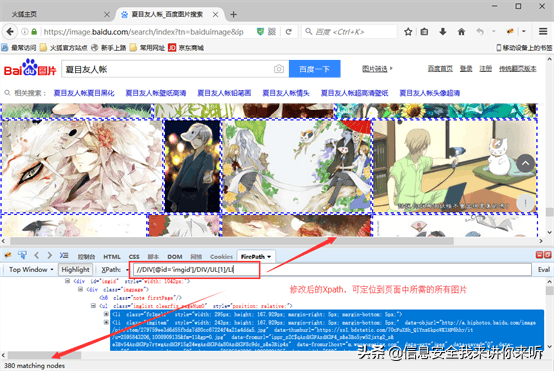
3)我们需要一条能够定位到网页中全部所需图片的Xpath。观察网页源码并将Xpath修改为://DIV[@id=imgid]/DIV/UL[1]/LI,网页中全部所需的图片均被定位了
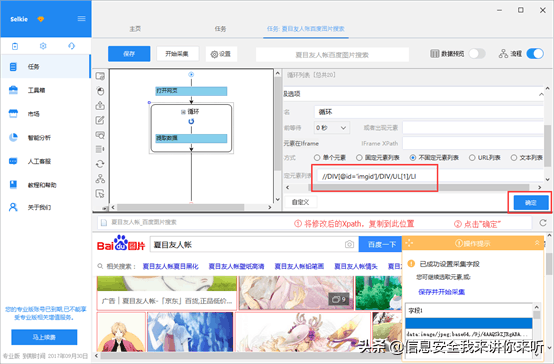
4)将修改后的Xpath://DIV[@id=imgid]/DIV/UL[1]/LI,复制粘贴到八爪鱼中相应位置,完成后点击"确定"
5)点击"保存",再点击"开始采集",这里选择"启动本地采集"
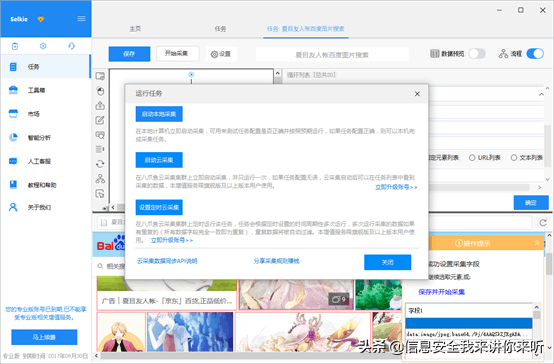 步骤4:数据采集及导出
步骤4:数据采集及导出1)采集完成后,会跳出提示,选择导出数据
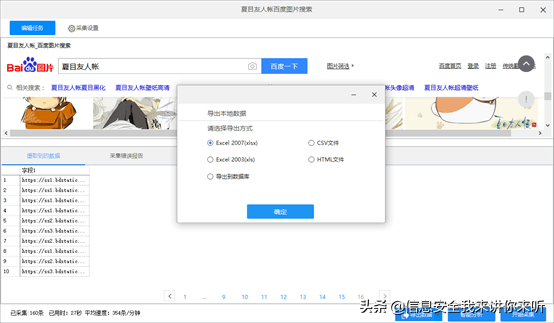
2)选择合适的导出方式,将采集好的数据导出
 步骤5:将图片URL批量转换为图片
步骤5:将图片URL批量转换为图片经过如上操作,我们已经得到了要采集的图片的URL。接下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。
图片批量下载工具:
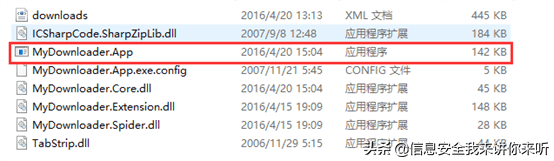
1)下载八爪鱼图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件
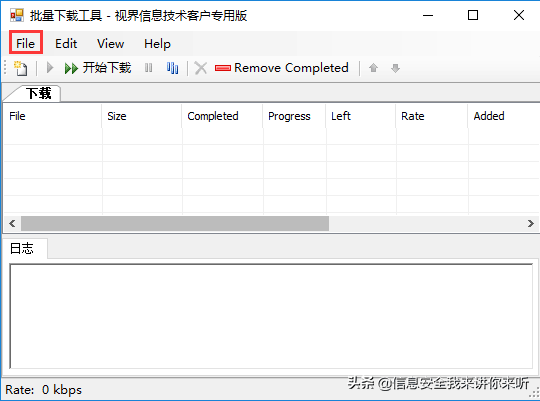
2)打开File菜单,选择从EXCEL导入(目前只支持EXCEL格式文件)
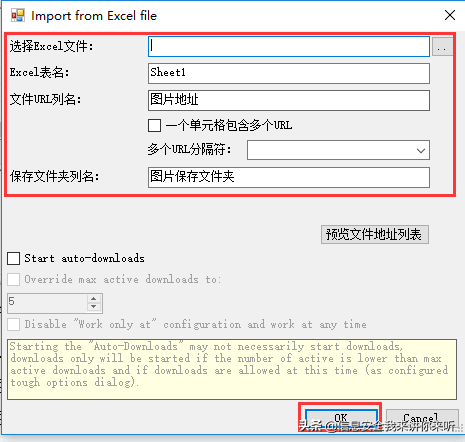
3)进行相关设置,设置完成后,点击OK即可导入文件
选择EXCEL文件:导入你需要下载图片地址的EXCEL文件
EXCEL表名:对应数据表的名称
文件URL列名:表内对应URL的列名称
保存文件夹名:EXCEL中需要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片存放至不同文件夹
如果要把文件保存到文件夹,则路径需要以""结尾,例如:"D:同步",如果要下载后按照指定的文件名保存,则需要包含具体的文件名,例如"D:同步1.jpg"
如果下载的文件路径和文件名完全一样,则原先存在的文件会被删除
版权声明:本文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,不做权威认证,不拥有所有权,不承担相关法律责任,转载请注明出处。本文地址:https://www.sip-server.cn/38056.html
